Integrating Bryntum Gantt With a Neo4j Database

We strive to keep posts updated, but code samples may sometimes be outdated. Humans, see the Bryntum documentation; agents, https://mcp.bryntum.com for the latest info.
Bryntum components readily integrate with a range of backend services. Whether you’re working with SQLite, a non-SQL database like MongoDB, or even a graph database like Neo4j, Bryntum offers seamless integration. In this blog, we’ll integrate Bryntum Gantt with a Neo4j database.
What is Neo4j?
Neo4j is a robust, high-performance graph database that centres around nodes (representing entities) and edges (representing relationships between these entities). Unlike traditional relational databases that rely on tables, rows, and columns, Neo4j uses a graph structure, which allows for more natural data modelling, mainly when dealing with highly interconnected data.
One of Neo4j’s standout features is its ability to visually represent your database, enabling users to explore and understand the data through a graphical interface intuitively. This visualization capability makes it easier to identify patterns, detect anomalies, and derive insights from complex data structures. Additionally, Neo4j supports a query language called Cypher, explicitly designed for working with graph data, making it simpler and more efficient to perform operations like searching, traversing, and analyzing node relationships.
Learn more about Neo4j Workspace.
Getting started
To get started, clone the Bryntum Gantt Frontend Starter Repository and install the dependencies by running:
npm install
The frontend code’s final result is in the repository (completed-app). Follow this guide for detailed steps on installing Bryntum Gantt with the npm CLI.
Now run the Bryntum Gantt chart locally with the following command:
npm run dev
You’ll see a basic Bryntum Gantt chart in the browser:
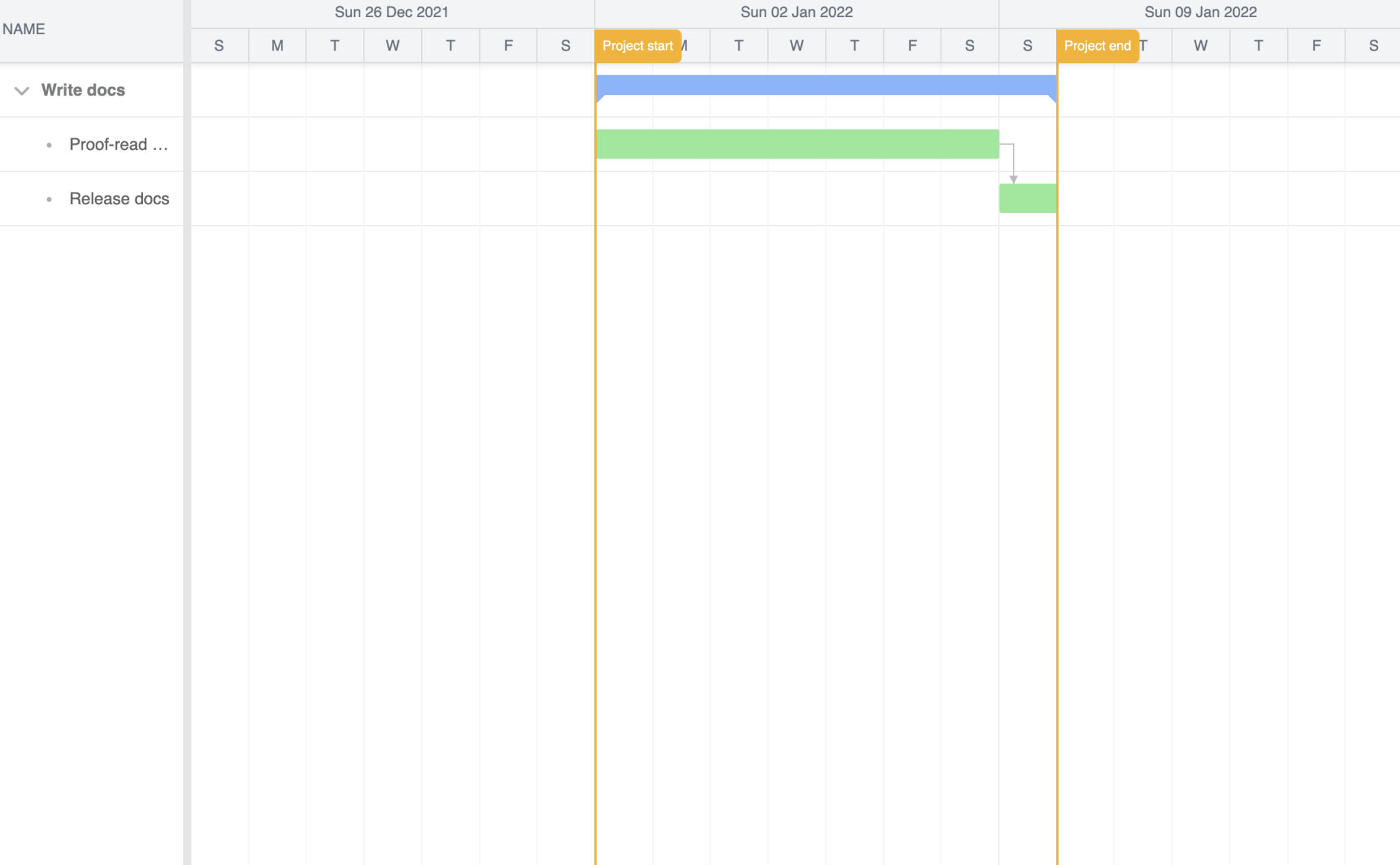
Modifying the Bryntum Gantt chart
Let’s add some features to the basic Bryntum Gantt chart, starting with the Resources column.
Head over to the main.js file and replace the columns array with the following code:
import { Gantt, AssignmentField, StringHelper } from "@bryntum/gantt";
new Gantt({
// .. other configs
columns: [
{ type: "name", width: 250 },
{
type: "resourceassignment",
width: 250,
showAvatars: true,
editor: {
type: AssignmentField.type,
picker: {
height: 350,
width: 450,
features: {
filterBar: true,
group: "resource.city",
headerMenu: false,
cellMenu: false,
},
// The extra columns are concatenated onto the base column set.
columns: [
{
text: "Calendar",
// Read a nested property (name) from the resource calendar.
field: "resource.calendar.name",
filterable: false,
editor: false,
width: 85,
},
],
},
},
}
],
}You’ll see an empty Assigned Resources column that we’ll populate with data soon.
Updating the data
There is a public/data.json file that we will use to replace the existing tasks and dependencies.
Create a new ProjectModel instance:
import { ProjectModel } from "@bryntum/gantt";
const project = new ProjectModel({
autoLoad: true,
autoSync: true,
transport: {
load: {
url: "data.json",
}
}
});
Replace the project object in the new Gantt() instance:
new Gantt({
// other configs
project: project
})
Now remove the startDate and endDate from Gantt instance:
startDate: new Date(2022, 0, 1),
endDate: new Date(2022, 0, 10),
We no longer need these fields because they are defined in the data.json file.
At this point, the Bryntum Gantt chart will look like this:
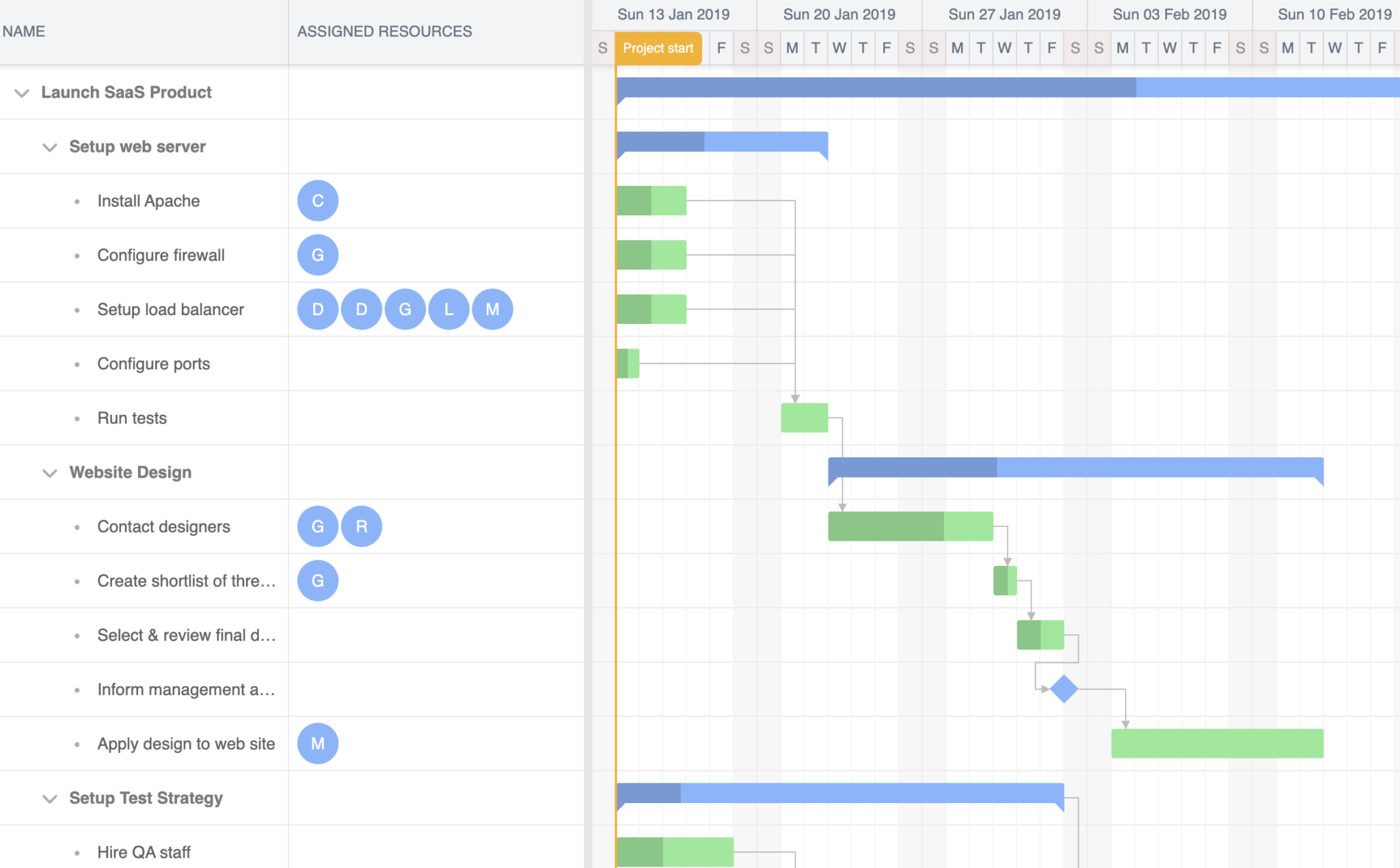
Adding resource images
Currently, the resource thumbnails display initials. Replace the initials with avatar images by adding the following path to the Gantt instance:
new Gantt({
resourceImageFolderPath: "./users/",
})
The public/users folder is used to store the headshots. The Bryntum Gantt chart looks for the image value in resourceStore and finds the image matching that name in the users folder.
Now, the demo Bryntum Gantt chart will look like this:
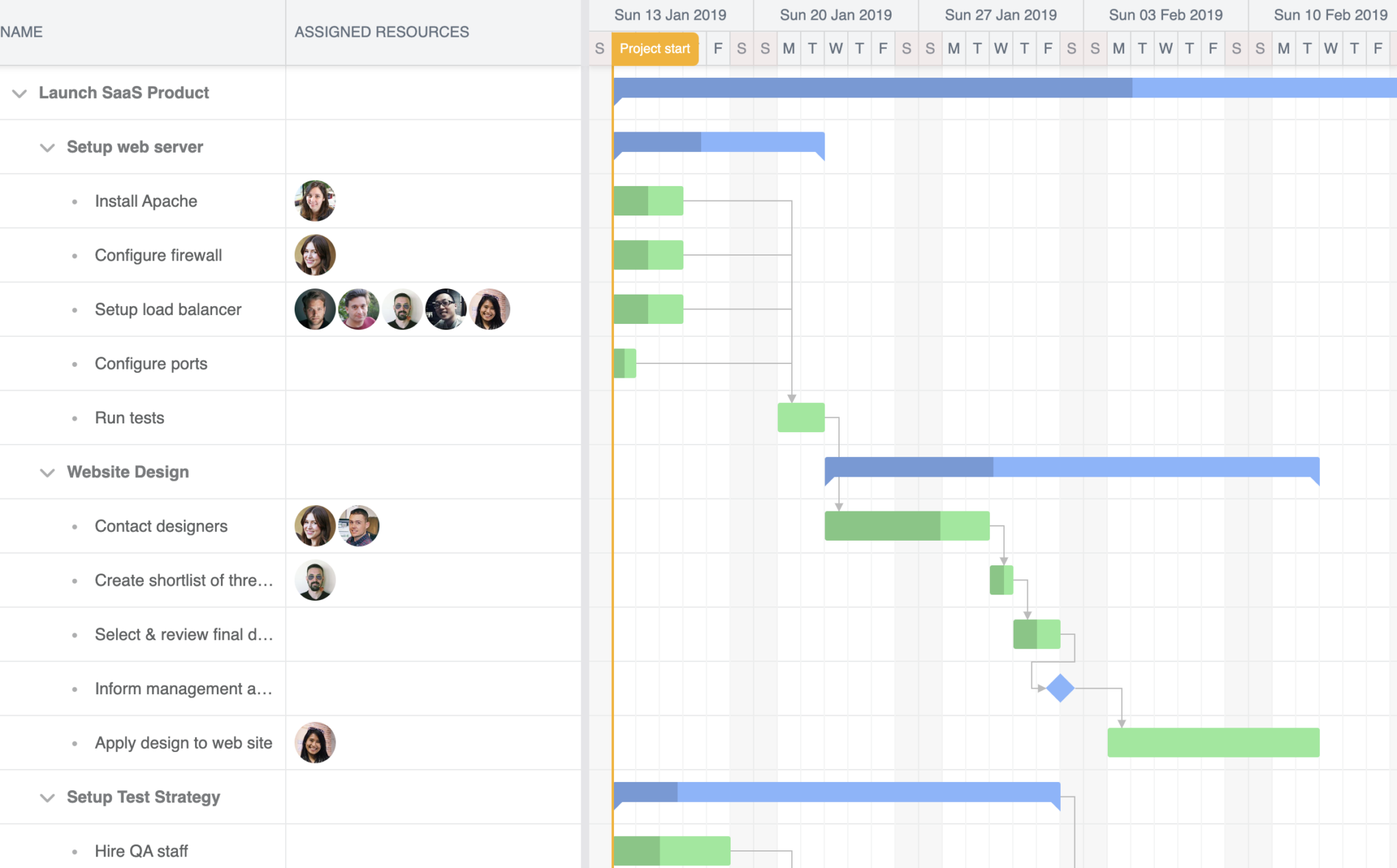
We’re almost done with the front end. Currently, data is fetched from the public/data.json file. We’ll modify the Gantt to integrate it with a backend server that uses Neo4j, but first, let’s set up the backend server.
Setting up the backend server
Clone the Neo4j backend starter repository and install the dependencies by running :
npm install
The completed-app branch contains the final backend code of this project.
Setting up the Neo4j database
Create a Neo4j account if you don’t have one. Once you’ve created an account, go to the Neo4j console, and under AuraDB, select Instances, then New Instance.
Copy the generated database credentials and add them to your .env file.
Next, install the Neo4j driver:
npm i neo4j-driver
Connecting to the database
In the index.js file, add the following code after const DBNAME = process.env.NEO4J_DBNAME || "neo4j";
(async () => {
try {
driver = neo4j.driver(URI, neo4j.auth.basic(USER, PASSWORD));
const serverInfo = await driver.getServerInfo();
console.log("Connection established");
console.log(serverInfo);
} catch (err) {
console.log(`Connection errorn${err}nCause: ${err.cause}`);
}
})();
This creates a connection with the database and ensures the connection works smoothly.
Loading data from the database
Now, we’ll handle reading and loading data from the database.
In the index.js file, replace the ”/load” request content with the following code:
const session = driver.session({ database: DBNAME });
try {
const [tasks, dependencies, resources, assignments, calendars, project] =
await session.readTransaction(async (txc) => {
return await Promise.all([
getTasks(txc),
getDependecies(txc),
getResources(txc),
getAssignments(txc),
getCalendars(txc),
getProject(txc),
]);
});
res.send({
success: true,
project: project,
calendars: {
rows: calendars,
},
tasks: {
rows: tasks,
},
dependencies: {
rows: dependencies,
},
resources: {
rows: resources,
},
assignments: {
rows: assignments,
},
});
} catch (error) {
res.send({
success: false,
// pass raw exception message to the client as-is
// please replace with something more human-readable before using this on production systems
message: error.message,
});
} finally {
await session.close();
}
The calendars, tasks, dependencies, resources, and assignments data is read from the database and returned as a response.
We need to make the function async because it uses await:
app.get("/load", async (req, res) => {
// code
})
Now, let’s set up interactions with the database. We’ll use Cypher queries and transform the data into a tree structure.
Create a helper.js file and add the following code to the helper.js file:
function buildTreeArray(flatArray) {
const nodeMap = {};
const result = [];
flatArray.forEach((item) => {
nodeMap[item.id] = { ...item, children: [] };
});
flatArray.forEach((item) => {
const node = nodeMap[item.id];
if (item.parentId !== null) {
nodeMap[item.parentId].children.push(node);
} else {
result.push(node);
}
});
return result;
}
async function getTasks(txc) {
var result = await txc.run(`
match (n:Task)
return collect(apoc.map.merge( n{.*}, {
parentId: [ (n)-[:PARENT_TASK]->(p) | p.id ][0],
baselines: [ (n)-[:HAS_BASELINE]->(b) | b{.*} ]
} )) as tasks
`);
response = result.records.map((record) => record.get("tasks"))[0];
tasks = buildTreeArray(response);
return tasks;
}
async function getDependecies(txc) {
var result = await txc.run(`
match (f:Task)-[d:DEPENDS_ON]->(t:Task)
return collect(
apoc.map.merge( d{.*},
{from:f.id, to:t.id})
) as dependencies
`);
return result.records.map((record) => record.get("dependencies"))[0];
}
async function getResources(txc) {
var result = await txc.run(`
match (r:Resource)
return collect(r{.*}) as resources
`);
return result.records.map((record) => record.get("resources"))[0];
}
async function getAssignments(txc) {
var result = await txc.run(`
match (t:Task)-[d:ASSIGNED_TO]->(r:Resource)
return collect(
apoc.map.merge( d{.*},
{event:t.id, resource:r.id})
) as assignments
`);
return result.records.map((record) => record.get("assignments"))[0];
}
async function getCalendars(txc) {
var result = await txc.run(`
match (c:Calendar)
where not exists { ()-[:HAS_CHILD]->(c)}
return collect(c{.*, children: [ (c)-[:HAS_CHILD]->(cc:Calendar) | cc{.*, intervals: [ (cc)-[:HAS_INTERVAL]->(ci) | apoc.map.removeKey(properties(ci),'id' ) ]}]}) as calendars
`);
return result.records.map((record) => record.get("calendars"))[0];
}
async function getProject(txc) {
var result = await txc.run(`
match (p:Project)
return p{.*} as project limit 1
`);
return result.records.map((record) => record.get("project"))[0];
}
module.exports = {
getProject,
getCalendars,
getAssignments,
getResources,
getTasks,
getDependecies,
};
Also, import it in index.js:
const {
getProject,
getCalendars,
getAssignments,
getResources,
getTasks,
getDependecies,
} = require("./helper");
Each function gets a data store type from the database. For example, the getTasks function returns task data from the database.
Start the server by running npm start and go to localhost:3000/load in your browser to see the response. The response is currently empty as we haven’t added any data yet. We need to add the request before we add data using a Node.js script.
Syncing the data with the database
The ”/sync” endpoint is used to create, update, and delete a task, resource, dependency, and other data store types.
Replace the ”/sync” request content with the following code:
const { requestId, tasks, resources, assignments, dependencies } = id_util(
req.body
);
const session = driver.session({ database: DBNAME });
try {
const [tasks_res, resources_res, assignments_res, dependencies_res] =
await session.writeTransaction(async (txc) => {
return await Promise.all([
syncTasks(txc, tasks),
syncResources(txc, resources),
syncAssignments(txc, assignments),
syncDependencies(txc, dependencies),
]);
});
const response = { requestId, success: true };
// if task changes are passed
if (tasks) {
const rows = tasks_res;
// if got some new data to update client
if (rows) {
response.tasks = { rows };
}
}
if (resources) {
const rows = resources_res;
// if got some new data to update client
if (rows) {
response.resources = { rows };
}
}
if (assignments) {
const rows = assignments_res;
// if got some new data to update client
if (rows) {
response.assignments = { rows };
}
}
if (dependencies) {
const rows = dependencies_res;
// if got some new data to update client
if (rows) {
response.dependencies = { rows };
}
}
res.send(response);
} catch (error) {
console.log(error.message);
res.send({
requestId,
success: false,
// pass raw exception message to the client as-is
// please replace with something more human readable before using this on production systems
message: error.message,
});
} finally {
await session.close();
}Add the following to helper.js file:
function id_util(data) {
const phantomToIdMap = new Map();
extractPhantomId(data, phantomToIdMap);
replacePhantomId(data, phantomToIdMap);
return data;
}
const extractPhantomId = (obj, phantomToIdMap) => {
let phantomIdUsedAsId = false;
let phantomId = "";
Object.keys(obj).forEach((key) => {
if (typeof obj[key] === "object" && obj[key] !== null) {
extractPhantomId(obj[key], phantomToIdMap);
} else if (key === "$PhantomId") {
phantomToIdMap.set(obj[key], crypto.randomUUID());
phantomId = obj[key];
} else if ((phantomId != "") & (obj[key] === phantomId))
phantomIdUsedAsId = true;
});
if (!phantomIdUsedAsId & (phantomId != "") & !("id" in obj)) {
obj["id"] = phantomId;
}
};
const replacePhantomId = (obj, phantomToIdMap) => {
Object.keys(obj).forEach((key) => {
if (typeof obj[key] === "object" && obj[key] !== null) {
replacePhantomId(obj[key], phantomToIdMap);
} else if (phantomToIdMap.has(obj[key]) & !(key === "$PhantomId")) {
obj[key] = phantomToIdMap.get(obj[key]);
}
});
};
async function syncTasks(txc, changes) {
if (changes) {
let rows;
if (changes.added) {
rows = await createTasks(txc, changes.added);
}
if (changes.updated) {
await updateTasks(txc, changes.updated);
}
if (changes.removed) {
await deleteTasks(txc, changes.removed);
}
// if got some new data to update client
return rows;
}
}
async function syncResources(txc, changes) {
if (changes) {
let rows;
if (changes.added) {
rows = await createResources(txc, changes.added);
}
if (changes.updated) {
await updateResources(txc, changes.updated);
}
if (changes.removed) {
await deleteResources(txc, changes.removed);
}
// if got some new data to update client
return rows;
}
}
async function syncAssignments(txc, changes) {
if (changes) {
let rows;
if (changes.added) {
rows = await createAssignments(txc, changes.added);
}
if (changes.updated) {
await updateAssignments(txc, changes.updated);
}
if (changes.removed) {
await deleteAssignments(txc, changes.removed);
}
// if got some new data to update client
return rows;
}
}
async function syncDependencies(txc, changes) {
if (changes) {
let rows;
if (changes.added) {
rows = await updateDependencies(txc, changes.added);
}
if (changes.updated) {
await updateDependencies(txc, changes.updated);
}
if (changes.removed) {
await deleteDependencies(txc, changes.removed);
}
// if got some new data to update client
return rows;
}
}
async function createTasks(txc, added) {
var result = await txc.run(
`
unwind $tasks as task
create (n:Task{id: coalesce(task.id, randomUuid())})
set n+= apoc.map.removeKeys(task,['baselines','children','parentId']),
n.`$PhantomId` = null
with n, task,
case task.parentId is null when true then [] else [task.parentId] end as parents
foreach( parent in parents |
merge (p:Task{id:parent})
merge (n)-[:PARENT_TASK]->(p)
)
return collect(apoc.map.merge( n{.*}, {
parentId: [ (n)-[:PARENT_TASK]->(p) | p.id ][0],
baselines: [ (n)-[:HAS_BASELINE]->(b) | b{.*} ],
`$PhantomId`:task.`$PhantomId`
})) as tasks
`,
{ tasks: added }
);
return result.records.map((record) => record.get("tasks"))[0];
}
function addChildren(task_id, children, tasks, child_task_rels) {
if (children) {
for (task of children) {
task_copy = Object.assign({}, task);
delete task_copy["children"];
tasks.push(task_copy);
child_task_rels.push({ parent: task_id, child: task_copy.id });
addChildren(task.id, task.children, tasks, child_task_rels);
}
}
}
async function updateTasks(txc, updated) {
tasks = [];
child_task_rels = [];
for (task of updated) {
const task_copy = structuredClone(task);
delete task_copy["children"];
tasks.push(task_copy);
addChildren(task.id, task.children, tasks, child_task_rels);
}
var result = await txc.run(
`
unwind $tasks as task
merge (n:Task{id:task.id})
set n+= apoc.map.removeKeys(task,['baselines'])
with n, task
call {
with n, task
with n, task
where task.baselines is not null
optional match (n)-[r:HAS_BASELINE]->(b)
delete r, b
return count(*) as deleted
}
foreach ( bl in task.baselines | create (b:Basline) set b+=bl merge (n)-[:HAS_BASELINE]->(b))
with collect(task) as tasks
unwind $rels as rel
match (p:Task{id:rel.parent}), (c:Task{id:rel.child})
merge (p)<-[:PARENT_TASK]-(c)
return tasks
`,
{ tasks: tasks, rels: child_task_rels }
);
return result.records.map((record) => record.get("tasks"))[0];
}
async function deleteTasks(txc, removed) {
var result = await txc.run(
`
unwind $tasks as task
match (n:Task{id:task.id})-[rels:HAS_BASELINE*0..1]->(b)
foreach (r in rels | delete r)
detach delete n,b
return collect(task) as tasks
`,
{ tasks: removed }
);
return result.records.map((record) => record.get("tasks"))[0];
}
async function createResources(txc, added) {
var result = await txc.run(
`
unwind $resources as resource
create (n:Resource{id: coalesce(resource.id, randomUuid())})
set n+= resource,
n.`$PhantomId` = null
return collect(apoc.map.merge( n{.*},
`$PhantomId`: resource.`$PhantomId`
)) as resources
`,
{ resources: added }
);
return result.records.map((record) => record.get("resources"))[0];
}
async function updateResources(txc, updated) {
var result = await txc.run(
`
unwind $resources as resource
merge (n:Resource{id:resource.id})
set n+= resource
return collect(resource) as resources
`,
{ resources: updated }
);
return result.records.map((record) => record.get("resources"))[0];
}
async function deleteResources(txc, removed) {
var result = await txc.run(
`
unwind $resources as resource
match (n:Resource{id:resource.id})
detach delete n
return collect(resource) as resources
`,
{ resources: removed }
);
return result.records.map((record) => record.get("resources"))[0];
}
async function createAssignments(txc, added) {
var result = await txc.run(
`
unwind $assignments as assignment
with assignment,
case assignment.id is null
when true then randomUuid()
else assignment.id
end as assgnId
merge (t:Task{id: assignment.event})
merge (r:Resource{id: assignment.resource})
merge (t)-[d:ASSIGNED_TO{id:assgnId}]->(r)
set d.units = assignment.units
return collect(
apoc.map.merge( d{.*},
{
event:t.id,
resource:r.id,
`$PhantomId`: assignment.`$PhantomId`
})
) as assignments
`,
{ assignments: added }
);
return result.records.map((record) => record.get("assignments"))[0];
}
async function updateAssignments(txc, updated) {
var result = await txc.run(
`
unwind $assignments as assignment
with assignment,
case assignment.id is null
when true then randomUuid()
else assignment.id
end as assgnId,
optional match (t)-[old_assignment:ASSIGNED_TO{id:assignment.id}]->(r)
with assignemnt, assignId, old_assignment
coalesce(assignment.event, t.id) as tid,
coalesce(assignment.resource, r.id) as rid,
coalesce(assignment.units, old_assignment.units) as units
delete old_assignment
merge (t:Task{id: tid})
merge (r:Resource{id: rid})
merge (t)-[d:ASSIGNED_TO{id:assgnId}]->(r)
set d.units = assignment.units
return collect(
apoc.map.merge( d{.*},
{
event:t.id,
resource:r.id
})
) as assignments
`,
{ assignments: updated }
);
return result.records.map((record) => record.get("assignments"))[0];
}
async function updateDependencies(txc, updated) {
var result = await txc.run(
`
unwind $dependencies as dependency
with dependency,
case dependency.id is null
when true then randomUuid()
else dependency.id
end as depId,
coalesce(dependency.fromTask, dependency.from) as fromId,
coalesce(dependency.toTask, dependency.to) as toId
merge (t:Task{id: fromId})
merge (r:Task{id: toId})
merge (t)-[do:DEPENDS_ON{id:depId}]->(r)
set do.type=dependency.type,
do.lag=dependency.lag,
do.lagUnit = dependency.lagUnit
return collect(
apoc.map.merge( do{.*},
{
fromTask:t.id,
toTask:r.id,
`$PhantomId`: dependency.`$PhantomId`
})
) as dependencies
`,
{ dependencies: updated }
);
return result.records.map((record) => record.get("dependencies"))[0];
}
async function deleteDependencies(txc, updated) {
var result = await txc.run(
`
unwind $dependencies as dependency
match ()-[do:DEPENDS_ON{id:dependency.id}]->()
delete do
return collect(dependency) as dependencies
`,
{ dependencies: updated }
);
return result.records.map((record) => record.get("dependencies"))[0];
}
async function deleteAssignments(txc, removed) {
var result = await txc.run(
`
unwind $assignments as assignment
match ()-[old_assignment:ASSIGNED_TO{id:assignment.id}]->()
delete old_assignment
return collect(assignment) as assignments
`,
{ assignments: removed }
);
return result.records.map((record) => record.get("assignments"))[0];
}These helper functions sync tasks, assignments, dependencies, and resources. Make sure to export the following functions from helper.js:
module.exports = {
id_util,
syncTasks,
syncAssignments,
syncDependencies,
syncResources,
};
Lastly, import it in index.js:
const {
getProject,
getCalendars,
getAssignments,
getResources,
getTasks,
getDependecies,
id_util,
syncTasks,
syncAssignments,
syncDependencies,
syncResources,
} = require("./helper");
Migrating the data
The migration.js file has Neo4j queries to migrate data from data.json to the newly created AuraDB.
The backend project doesn’t have any data.json files. Copy it from the frontend starter project, located at public/data.json to the backend’s root folder.
Next, export the following functions from helper.js:
updateProject,
updateCalendars,
updateTasks,
updateResources,
updateDependencies,
createAssignments,
Then execute the following command in the root of the project:
node migration.js
Confirm the success of the migration by opening your AuraDB instance on the Neo4j console.
Integrating with the backend
Switch back to your front-end project. In the main.js file, replace the transport object in the new ProjectModel({}) instance with the following code:
transport: {
load: {
url: "/load",
},
sync: {
url: "/sync",
},
}
The ”/load” endpoint gets the data, and the ”sync” endpoint is used to add, update, and delete the data. Start the backend and frontend server with npm start and visit https://localhost:5173/
The Bryntum Gantt chart will load and sync the data with the Neo4j database.
The final code is under the complete-app branch in Frontend and Backend repositories.
Conclusion
Bryntum components are incredibly flexible and seamlessly integrate with any backend database using REST APIs. Their adaptability lets you effortlessly switch to different databases, like MongoDB, simply by modifying the backend.
If you’re new to Bryntum Gantt, our free 45-day trial is the perfect opportunity to explore the powerful capabilities of Bryntum products in your projects. Our forums are always open if you have any questions or need support.
Visit our live demos to discover more Bryntum Gantt features:
Multiple Gantt Charts demo
Planned percent done demo
More Bryntum Gantt demos